Multimodal Fusion of EMG and Vision for Human Grasp Intent Inference in Prosthetic Hand Control
Research Digest
Author(s): Doran Amos, Neil M. Thomas, Kai Dierkes
November 2, 2021

Image credit: Mechanical engineer aids with prosthetic arm from Unsplash by ThisisEngineering.
Improving amputees’ quality of life with better functional prostheses
In 2005, an estimated 1.6 million people in the USA were living with the loss of one or more limbs, with this number expected to double by 2050. Around 80% of upper-limb amputees who have lost one or both hands currently use a cosmetic prosthesis, which does not restore the lost function needed for everyday tasks at home and at work.
To allow it to be used seamlessly in everyday life, a prosthesis needs to mimic the natural human behavior of pre-forming the grasp type of the hand prior to reaching the object—but creating such a functional prosthesis that can do this reliably and intuitively is a challenge.
Artificial intelligence (AI)-driven functional prostheses aim to address this by allowing the wearer's intended arm and hand movements to be inferred in advance based on environmental and physiological signals.
Combining electromyography and eye tracking to improve functional prostheses
Existing AI-driven functional prostheses have focused on using a single source of data to guide the reaching and grasping actions of a prosthetic robot arm and hand. However, inferring the intended action from one source alone can be unreliable and susceptible to errors.
For example, recording electromyography (EMG) signals from muscles in the forearm offers an intuitive way for the amputee to control the robotic prosthesis. However, errors can creep in as the recording electrodes shift or skin impedance changes over time.
Recently, a research team led by Gunar Schirner at the Embedded Systems Laboratory at Northeastern University, Boston, MA, USA investigated whether combining data from two independent sources might help to improve the performance of functional prostheses.
They sought to develop a hybrid EMG–visual AI algorithm for robotic prostheses that would combine EMG recordings from muscles in the forearm with world-camera and eye-gaze data from a Pupil Core headset to predict the required grasp type for different objects (Figure 1).
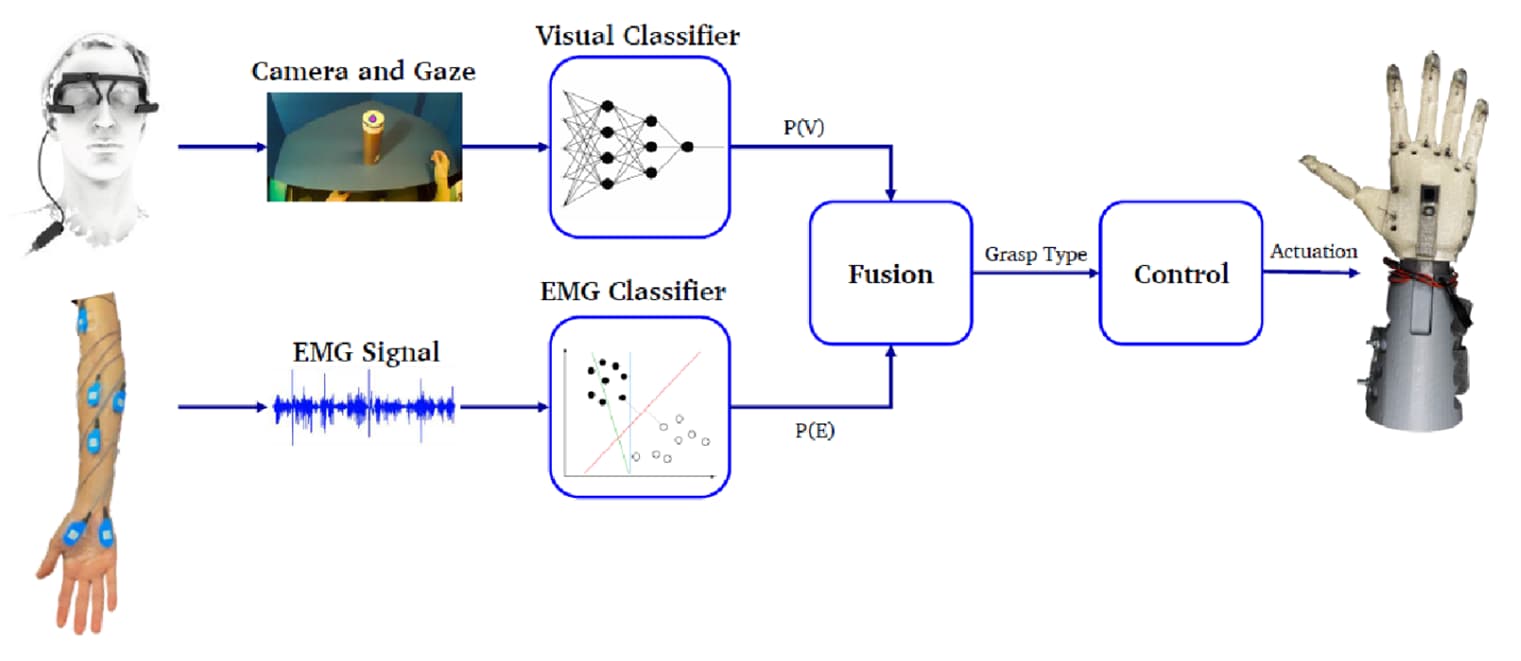
Figure 1. Proposed model for “fusing” visual- and EMG-based grasp estimation to control the grasp type of a robotic hand. In the present study, the researchers recorded world-camera, eye-gaze, and EMG data while subjects without limb damage reached for and grasped objects. These signals were used to train visual and EMG classifiers, whose output probabilities were combined to estimate objects and grasp types.
Leveraging AI to predict grasp type
To train and test the hybrid AI algorithm, a group of experimental subjects without limb damage were asked to pick up a variety of objects using predefined grasp types, e.g. scissors with a "distal grip", or a board eraser with a "palmar grip" (Figure 2).

Figure 2. Object grasping task used to collect world-camera, eye-gaze, and EMG data. (A) Subjects were instructed to move a series of everyday objects between set locations on a flat surface using a predefined grasp type for each object (shown in B). During the task, world-camera and eye-gaze data were recorded using a Pupil Core headset, and EMG signals were recorded from the subject’s forearm. (B) Subjects were required to use one of 13 predefined grasp types (in addition to the neutral “open palm”) to pick up each of the objects.
World-camera, eye-gaze, and EMG signals were recorded during the task and then segmented into defined reaching, grasping/moving, and resting phases (Figure 3).
The world-camera data were used to train a visual classifier to identify objects in the subject’s field-of-view from 53 predefined possibilities, along with their corresponding grasp types. Eye-gaze location was then used to select between potential objects-of-interest in the visual field, based on bounding boxes defined by the classifier. Meanwhile the EMG classifier was trained to identify the most likely grasp type using the EMG signals from the subject’s forearm.
Benchmarking the AI
The researchers wanted to investigate if “fusing” the probabilities from the two classifiers would improve the accuracy and speed with which the correct grasp type could be determined. First, they examined the performance of the EMG or visual classifiers alone by analyzing the accuracy of grasp type estimation at each timepoint during the reaching, grasping, and returning phases.
EMG Classifier
When the EMG classifier was applied to task data that had not been used for training, the results showed that it was more than 80% accurate at identifying the correct grasp types throughout most of the reaching and grasping phases, with the accuracy peaking around the onset of grasping (Figure 3, blue line).
In addition, this classifier was able to predict the correct grasp type well before the grasp onset, which would give a robotic hand in a functional prosthesis time to pre-form its grasp type.
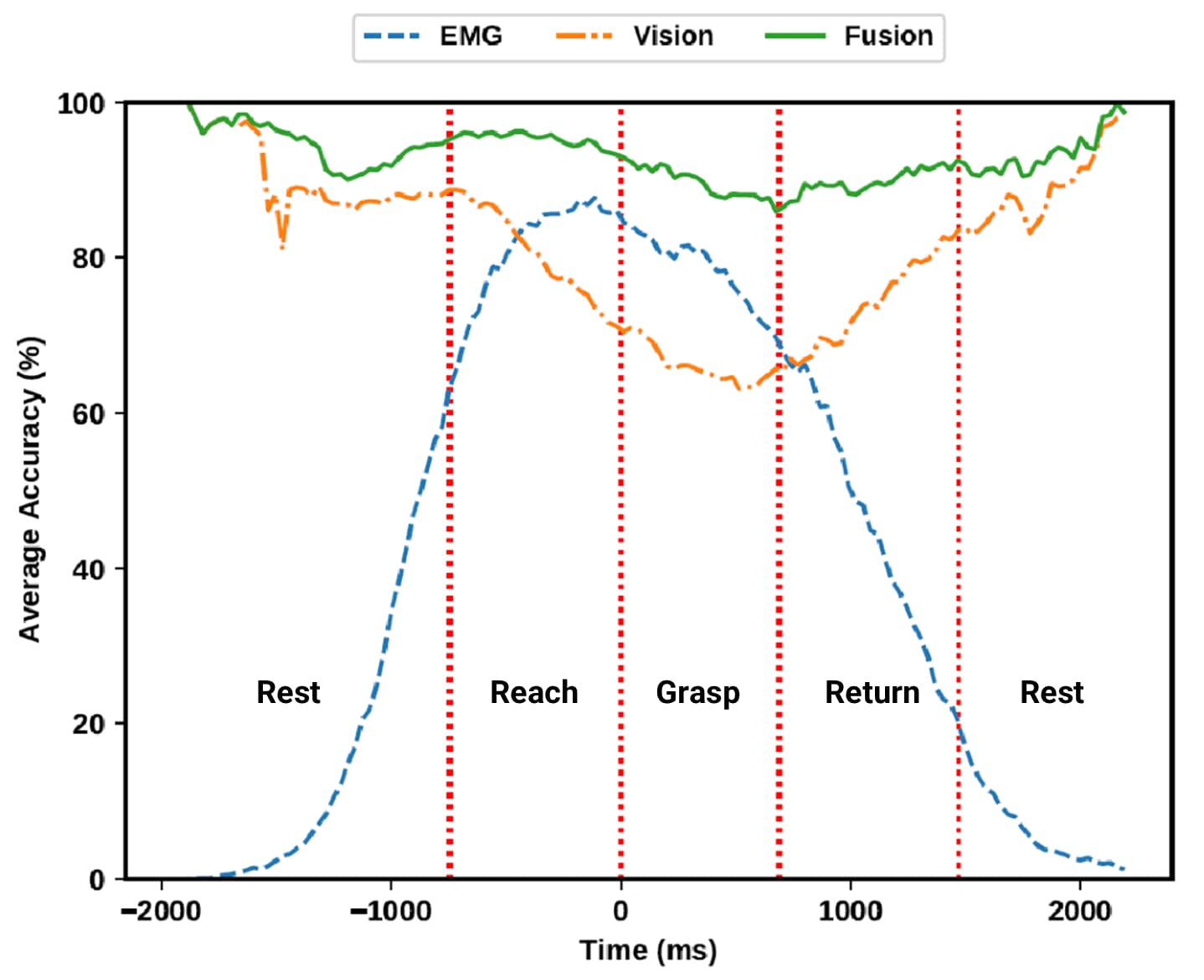
Figure 3. Accuracy of the EMG classifier (blue line), visual classifier (orange line), and fusion model combining both classifiers (green line) across the different phases of the task (grasp onsets across trials were aligned to 0 ms). The accuracy of the EMG classifier peaked around grasp onset and was lower before and after, while that of the visual classifier showed the opposite pattern. The fused classifiers were more accurate than either classifier alone, with the two sources of information complementing each other well.
Visual Classifier
Next, the researchers analyzed the accuracy of the visual classifier at identifying the correct object and corresponding grasp type across the different task phases. The classifier was around 85% accurate across most of the phases, although this accuracy dropped by about 20% during the grasping phase and the adjacent time periods, which was probably because the subject’s arm and hand occluded the object (Figure 3, orange line)
Combined Classifier
Finally, the researchers calculated the accuracy with which the fused EMG and visual classifiers could predict the correct grasp type. The combined classifier was found to increase the average accuracy of prediction by around 15% compared with that of either classifier alone (Figure 3, green line).
Importantly, the predictions of the visual and EMG classifiers complemented each other well, as the EMG classifier had the highest accuracy during the reaching and grasping phases, while the visual classifier showed the opposite pattern.
Towards more effective AI-driven functional prostheses
In their fascinating study, the research team successfully improved the accuracy of grasp-type prediction for functional prostheses by combining world-camera and eye-gaze data from a Pupil Core headset with forearm EMG recording. Crucially, the algorithms developed by the researchers were able to predict the correct grasp type well in advance of reaching an object.
We at Pupil Labs commend the research team on their success in developing effective methods for fusing multiple sources of information to accurately predict grasp type. We hope that their pioneering work will lead to the creation of better functional prostheses capable of seamless, human-like reaching and grasping, which can contribute to improving the quality of life of upper-limb amputees worldwide.
You can read the full paper here: Zandigohar, M., Han, M., Sharif, M., Gunay, S. Y., Furmanek, M. P., Yarossi, M., ... & Schirner, G. (2021). Multimodal Fusion of EMG and Vision for Human Grasp Intent Inference in Prosthetic Hand Control. arXiv preprint arXiv:2104.03893.
If you wish to include your published works or research projects in future digests, please reach out!
Copyright: Permission was granted by the corresponding author to re-use all figures. Figures cropped and resized for formatting purposes and captions and legends changed to align with the present digest content.